
文章插图
数据挖掘介绍
数据挖掘(Data Mining,DM):就是从大量数据(包括文本)中挖掘出隐含的、未知的、对决策有潜在价值的关系、模式和趋势,并用这些知识和规则建立用于决策支持的模型,提供预测性决策支持的方法、工具和过程;是利用各种分析工具在海量数据中发现模型和数据之间关系的过程 。这些模型和关系可以被企业用来分析风险、进行预测 。
数据挖掘的目的就是从数据中“淘金”,就是从数据中获取智能的过程,数据挖掘是提供了从数据到价值的解决方案 。
数据+工具+方法+目标+行动=价值 。
目前,数据挖掘已有一系列应用:
分类分析:有监督学习,将数据映射到事先定义的群组或类 。应用在将信用卡人分为低中高风险群等 。回归分析:用属性的历史数据预测未来趋势,应用预测哪些用户在未来半年会流失等 。聚类分析:无指导学习,在没有给定划分类的情况下,根据信息相似度进行信息聚类 。应用在对客户行为分析,对客户分层进行精准营销 。关联分析:发现事物间的关联规则或称相关程度,常用在交叉销售,交叉分析,著名的啤酒与尿布 。时序模式:已知的数据预测未来的值,回归不强调数据间的先后顺序 。偏差分析:来发现与正常情况不同的异常和变化,并进一步分析这种变化是有意的诈骗行为,还是正常的变化 。常用在防欺诈,以及保险领域 。
以上这些应用涉及的技术和工具各不相同,然而却可以依据统一的方法论来实行,并可以协同作战,解决许多有价值的商业问题 。
数据挖掘建模的一般过程
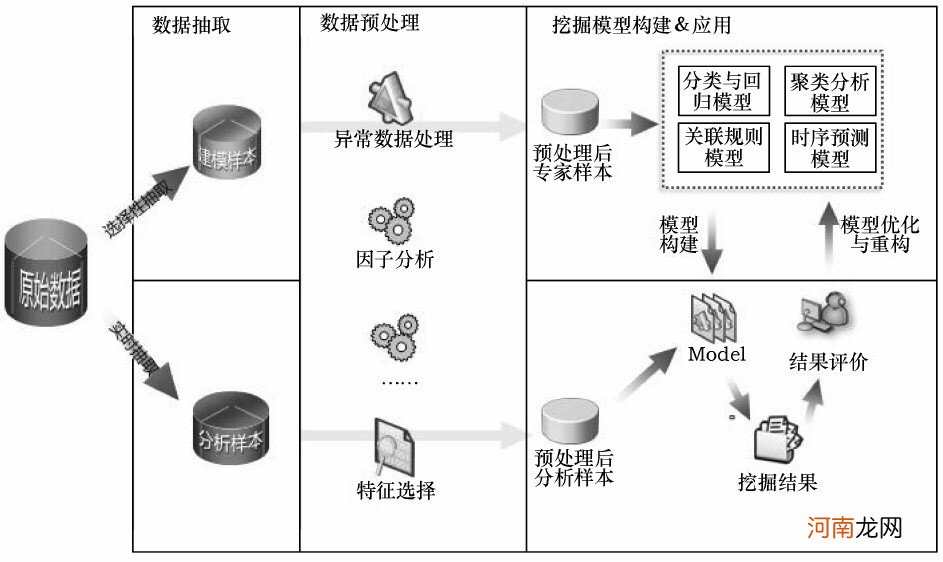
文章插图
第一步,数据准备
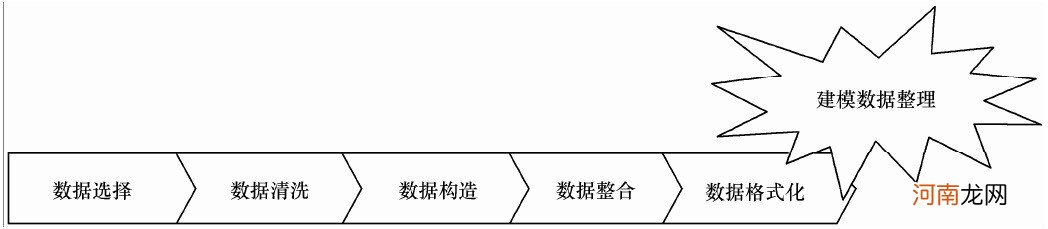
文章插图
数据选择主要考虑的包括:
哪些数据源可用?哪些数据与当前挖掘目标相关?如何保证取样数据的质量?是否在足够范围内有代表性?数据样本取多少合适?如何分类(训练集、验证集、测试集)?
选择数据的标准,一是相关性,二是可靠性,三是最新性,而不是动用全部企业数据 。通过数据样本的精选,不仅能减少数据处理量,节省系统资源,而且能通过数据的筛选,使想要反映的规律性更加突显出来 。
1)数据探索:数据清洗和构造
前面所叙述的数据选择,多少是带着人们对如何达到数据挖掘目的的先验认识进行操作的 。
当我们拿到了一个样本数据集后,它是否达到我们原来设想的要求?其中有没有什么明显的规律和趋势?有没有出现从未设想过的数据状态?因素之间有什么相关性?它们可区分成怎样一些类别?这都是要首先探索的内容 。
对所抽取的样本数据进行探索、审核和必要的加工处理,是保证预测质量所必需的 。可以说,预测的质量不会超过抽取样本的质量 。
数据探索主要包括:异常值分析、缺失值分析、相关分析、周期性分析、样本交叉验证等 。
2)数据预处理:整合和格式化
当采样数据维度过大,如何进行降维处理?采样数据中的缺失值如何处理?这些都是数据预处理要解决的问题 。
由于采样数据中常常包含许多含有噪声、不完整、甚至是不一致的数据 。显然对数据挖掘所涉及的数据对象必须进行预处理 。那么,如何对数据进行预处理以改善数据质量,并最终达到完善最终的数据挖掘结果的目的呢?
【数据挖掘的一般步骤 数据挖掘模型有哪些】
- 开零食不加盟哪里进货 未来适合在乡镇开的实体店
- 100元叠心的步骤教程 怎么用100元叠心啊
- 白萝卜的功效和禁忌 白萝卜的功效
- 积分换手机是真的吗 手机积分换手机能信吗
- 关于青蛙的资料 描写青蛙的优美句子
- 适合年轻人创业项目 适合年轻人的室内娱乐项目
- 小米10多少倍变焦 支持50倍变焦的手机有哪些
- 货代的专业知识 海运货代知识
- 淘宝热门店铺排名 淘宝最新人气排名按照什么排名的
- 家乐福的标志是什么意思 家乐福超市的标志有何含义