最近 , 本人负责的其中一个站点收录出现了异常 , 趁着周末有空讲述一下整个诊断过程 。核心问题有两点 , 服务器架构和网站程序架构导致的;本篇仅分享服务器架构导致的收录异常 。
首先 , 介绍一下自己 。本人就职于深圳某企业 , 长期混迹于乙方外包公司 , 众所周知seo外包公司接的是绝大部分是小企业网站 , 这些网站做的关键词往往也仅是改个TDK就完成排名的工作 。
再加上 , 目前绝大部分中小站点的架构很简单 , 开源CMS+单一云服务器(虚拟主机)+CDN(这还是有点运维能力公司) 。鉴于以上经验 , 导致本人完全没有意识到服务器架构方面也能出现问题 。
一、收录异常的发现
从(图1)可以和明显的看出 , 在3月中下旬收录是偏向正常的 , 问题出现在3.31日-4.25日之间出现了浮动 , 也就是说 , 这个区间一定是站点出现了问题导致收录异常 。
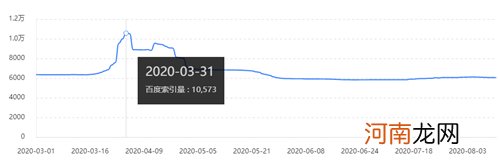
文章插图
本人开始按常规方法排查 , 特别是服务器日志有些参数没有排除注意 , 以至于导致了问题发现 , 具体如下:
1.1、站长平台模拟爬虫抓取 , 正常 。
1.2、搜索引擎爬虫抓取数量在提升 , 偏向正常 。这里有异常 , 排查伪蜘蛛爬虫在抓数据 , 真实百度爬虫确实也在增长 。
1.3、核心关键词排名浮动 , 但偏向且上升趋势靠前 , 目前核心大词处于前5名 , 正常 。
【SEO收录异常诊断:负载均衡架构导致的SEO问题及解决方案】1.4、服务器日志分析 , 爬虫对应的request_uri值(相对地址) , 暂属正常 , 请看下文 。
1.5、服务器日志是阿里云的日志 , http请求 , 7.18日、7.19日、7.20日以及7.26日出现小面积服务器500访问错误;但最多只出现有限的时间收录异常 , 不至于大范围不收录 。
在服务器访问日志分析中 , 一般需要注意的项是:爬虫抓取时间值 , 爬虫页面URL值 , 爬虫在页面抓取顺序 , 时间内爬虫抓取数量 , 另一说蜘蛛IP值有权重高低之分(本人不确定 , 故不参考)
页面URL值:一般服务器日志是相对地址 , 本人诊断出现的问题在于忽略host值 , 真实抓取URL应该是 , host+request_uri值组合 。
页面抓取顺序:可检验网站架构的爬行情况 , 大概可以知道爬虫在网站页面中的爬行顺序 , 可以辅助使用爬虫软件或者开发经典爬虫(PY , PHP等)的爬行情况作为参考
时间内爬虫抓取数量:检验网站页面总量和时间段内抓取量的占比 , 判断网站的受欢迎程度 。
说到这里 , 交代一下站点的服务器架构:
用的是负载均衡 , 文件服务器+数据服务器+前端服务器 , 数据服务器全部数据是由API接口、GET方式前端和app使用 , 网站URL是相对地址 。服务器之间自然用的也是内网通讯 。
综上 , 可能大家也看出有忽略的参数 , 是1.4中提到的日志host值 , 因为是相对地址 , host+request_uri才是抓取的完整地址 。一直忽略的Host值 , 原来是API的二级域名(图2)

文章插图
说到这里 , 大家可能已经基本上可以确定知道原因了 。
- 什么是SEO文章?seo文章的作用方法
- 做SEO优化有流量没转化怎么办?
- 如何发现异常染色体
- 胎心多久能查出来看两个时间段 但这些异常表现要慎重
- 胎动一小时多少次为正常 异常胎动是怎样的
- 新生儿睡觉翻白眼的原因新生儿“看似异常”的6个表现
- 公交车上女童哭喊找妈 同行妇女异常被疑拐带者
- seo那培训最好 大数据培训
- 宝宝长牙期间可能出现的异常
- 新生儿呼吸急促怎么回事 新生儿呼吸异常的两大危害