在日常工作中我们不可避免地会遇到慢SQL问题,比如笔者在之前的公司时会定期收到DBA彪哥发来的Oracle AWR报告,并特别提示我某条sql近阶段执行明显很慢,可能要优化一下等 。对于这样的问题通常大家的第一反应就是看看sql是不是写的不合理啊诸如:“避免使用in和not in,否则可能会导致全表扫描”“ 避免在where子句中对字段进行函数操作”等等,还有一种常见的反应就是这个表有没有加索引?绝大部分情况下,加了个索引基本上就搞定了 。
既然题目是《从千万级数据查询来聊一聊索引结构和数据库原理》,首先就来构造一个千万级的表直观感受下 。我们创建了一张user表,然后插入了1000万条数据,查询一下:
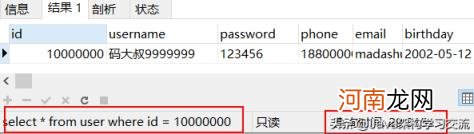
文章插图
用了近30秒的时间,这还是单表查询,关联查询明显会更让人无法忍受 。接下来,我们只是对id增加一个索引,再来验证一把:
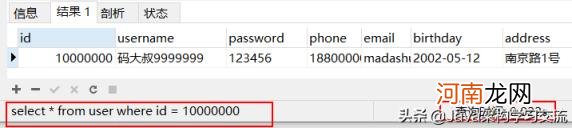
文章插图
从30s到0.02s,提升了足足1500倍 。为什么加了索引之后,速度嗖地一下子就上去了呢?我们从【索引数据结构】、【Mysql原理】两个方面入手 。
一、索引数据结构我们先来看下 MySQL官方对索引的定义:
这里面有2个关键词:高效查找、数据结构 。对于数据库来说,查询是我们最主要的使用功能,查询速度肯定是越快越好 。最基本的查找是顺序查找,更高效的查找我们很自然会想到二叉树、红黑树、Hash表、BTree等等 。
1.1 二叉树这个大家很熟悉了,他有一个很重要的特点: 左边节点的键值小于根的键值,右边节点的键值大于根的键值 。比如图1,它确实能明显提高我们的搜索性能 。但如果用来作为数据库的索引,明显存在很大的缺陷,但对于图2这种递增的id,存储后索引近似于变成了单边的链表,肯定是不合适的 。
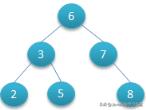
文章插图
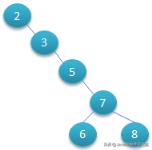
文章插图
1.2 红黑树也称之为平衡二叉树 。在JDK1.8后,HashMap对底层的链表也优化成了红黑树(后续文章我们可以讲讲Hashmap1.8之后的调整) 。平衡二叉树的结构使树的结构较好,明显提高查找运算的速度 。但是缺陷也同样很明显,插入和删除运算变得复杂化,从而降低了他们的运算速度 。对大数据量的支撑很不好,当数据量很大时,树的高度太高,如果查找的数据是叶子节点,依然会超级慢 。
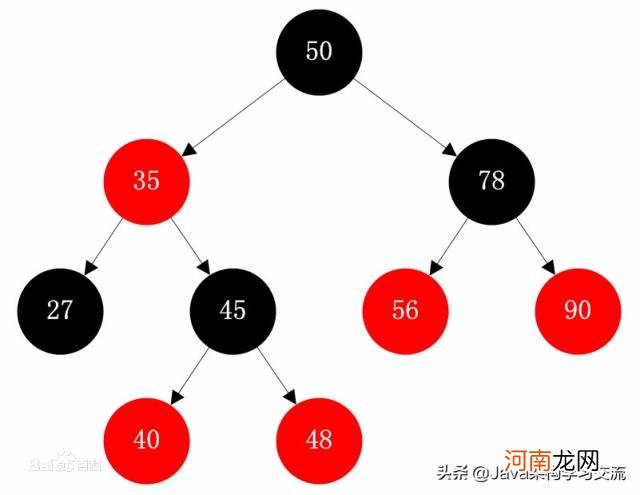
文章插图
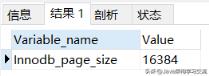
1.3 BTreeB-Tree是为磁盘等外存储设备设计的一种平衡查找树 。系统从磁盘读取数据到内存时是以磁盘块(block)为基本单位的,位于同一个磁盘块中的数据会被一次性读取到内存中 。在Mysql存储引擎中有页(Page)的概念,页是其磁盘管理的最小单位 。Mysql存储引擎中默认每个页的大小为16KB,查看方式:
mysql> show variables like \'innodb_page_size\';
文章插图
我们也可以将它修改为4K、8K、16K 。系统一个磁盘块的存储空间往往没有16K,因此Mysql每次申请磁盘空间时都会将若干地址连续磁盘块来达到页的大小16KB 。Mysql在把磁盘数据读入到磁盘时会以页为基本单位,在查询数据时如果一个页中的每条数据都能有助于定位数据记录的位置,这将会减少磁盘I/O次数,提高查询效率 。
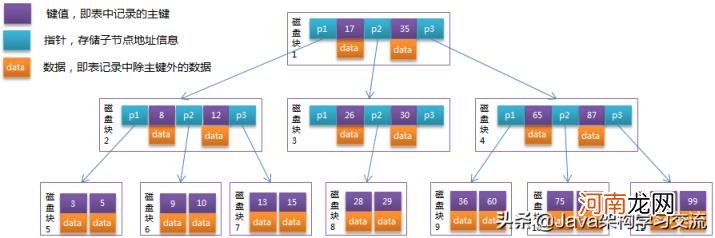
文章插图
- 病从口入祸从口出什么意思,语言是一门艺术?
- 你想象过你死后的世界吗 死后的世界是什么样子的
- 全球四大卫星导航系统 4个卫星导航定位系统分别是
- 为什么会下意识躲避一个人 男生下意识的躲避代表什么
- 下班做什么副业比较赚钱 在家能赚钱的副业
- 什么办法能挽回一个男人的心 最快挽回一个男人的方法
- 女人梦见蛇是什么预兆还被咬了 女人梦见蛇是什么预兆还被咬了手
- 自在飞花轻似梦下一句是什么自在飞花轻似梦的原文及翻译 自在飞花轻似梦下面一句是什么
- 神柏沙头什么动物 什么叫神柏沙头
- 解梦丢鞋 梦到丢鞋什么意思