在以往 , 我们要操作游戏角色进行近战的操作逻辑是:1、看到敌方目标 。2、锁定目标 , 向目标角色移动 。3、发动攻击 。
通过语音实现游戏操作 , 同样也是需要完成上面3个步骤 。让我们一起拆解一下作者在游戏中的指令 , 解析这套AI的工作流 。

文章插图
如上图所示 , 当作者说出“用战术三攻击中间的火深渊法师之后” 。让电脑执行了“语音指令识别——图像识别目标——角色行动”这三大步骤 , 整个过程有点类似于面向游戏定制了一个语音助手 , 就像“嘿 , Siri , 打开原神” 。
第一步:语音指令识别

文章插图
要让设备听懂我们的指令 , 我们就需要一个翻译官 , 将我们说的话转变成机器能够听得懂的计算机语言 , WeNet就是我们和机器对话的翻译官 。
WeNet是一个面向生产的端到端语音识别工具包 , 在单个模型中 , 它引入了统一的两次two-pass (U2) 框架和内置运行时来处理流式和非流式解码模式 。其语音识别正确率、实时率和延时性都有着非常出色表现 , 获得了京东、网易、英伟达、喜马拉雅等公司语音识别项目的采用 。
用WeNet识别咱们玩原神的语音指令 , 需要经过“准备训练数据”、“提取可选cmvn特征”、“生成标签令牌字典”、“准备WeNet数据格式”、“神经网格训练”、“用训练后的模型识别wav文件”、“导出模型”等6大步骤 。

文章插图
上面的东西用大白话讲就是 , 准备一些音频文件 , 同时标注我这些音频文件讲了啥 , 然后让机器去学习识别这些音频文件并生成标签 。上述训练完成以后 , 以后我们对机器说话 , WeNet就能把我们的话翻译成机器听得懂的话 。
第二步:解析语音指令特征
有了WeNet的助攻之后 , 我们实现了说出的话让机器听得懂我们说的是啥之后 , 我们还要让机器将听到的东西跟画面中的东西对应上 , 这就轮到第二个工具“X-VLM”登场了 。
X-VLM是一种基于视觉语言模型(VLM)的多粒度模型 , 由图像编码器、文本编码器和跨模态编码器组成 , 跨模态编码器在视觉特征和语言特征之间进行跨模态注意 , 以学习视觉语言对齐 。那具体这个工具是咋实现识别对象的呢?
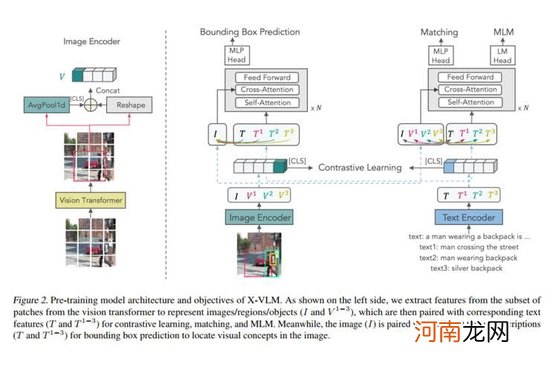
文章插图
上图展示了X-VLM的工作流程 。图片左侧为工具视觉概念的编码过程 。工具包的图像编码器基于Vision Transformer实现 , 输入的图片会被分成patch编码 。然后 , 给出任意一个边界框 , 灵活地通过取框中所有patch表示的平均值获得区域的全局表示 。接着该全局表示和原本框中所有的patch表示按照原本顺序整理成序列 , 作为该边界框所对应的视觉概念的表示 。
(字我都认识 , 连在一起怎么就是我不认识的样子了?)

文章插图
怎么文章看着看着变成做阅读理解了 , 让我们再多看亿眼 。

文章插图
上面这段话的意思 , 通俗点讲就是将图片切割成方块 , 并且预组合这些方块 。比如组合成“一个男人背着背包”的图片 , 或者组合成“男人背着背包过马路”的图片 。
- 湘菜特色
- aswl是什么梗
- 电磁炉对人有危害吗 电磁炉对人有副作用吗
- 中信银行的单币信用卡是一种什么卡 中信银行双币信用卡怎么免年费
- 怎样使用微信分身 怎样使用微信
- 智能家居十大排行榜,国内十大最好用智能家居?
- 韩国气垫排行榜10强,韩国什么气垫粉底液好用?
- 税收执法责任制概念 税收执法责任制的作用
- 吃葡萄干的八大好处,葡萄与葡萄干作用的区别?
- 哪个牌子的被套好,婚庆床上用品十大品牌?