MongoDB中,在使用到分片的时候,常常会用到chunk的概念,chunk是指一个集合数据中的子集,也可以简单理解成一个数据块,每个chunk都是基于片键的范围取值,区间是左闭右开 。例如,我们的片键是姓名的第二个字母,包含了A-Z这26中可能,理想情况下,划分为26个chunk,其中每个字母开头的姓名记录即为一个chunk 。
在数据写入的时候,mongos根据片键shard key的值来写入对应的chunk中,chunk可以表示的最小范围是单个唯一的shard key的值,只包含具体的单个片键值文档的chunk不能被分割,这个也比较容易理解,如果某个chunk只包含一个片键的值,如果对它进行分割,则代表一个片键值映射了2个chunk,下次遇到这个片键的文档时,mongos就不知道应该存放在哪个chunk当中了 。
chunk的大小如何确定???
在MongoDB中,chunk的默认大小是64MB,可以增加或者减少chunk的大小 。
chunk的大小不宜过小,如果chunk过小,好处是可以让数据更加均匀的分布,但是会导致chunk之间频繁的迁移,有一定的性能开销;同样的,chunk的大小不宜过大,过大的chunk size会导致数据分布不均匀,
chunk的分裂
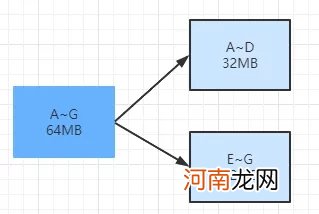
当某个chunk的值达到了chunk所能表示的最大值的时候,这个时候chunk不能无限增长,需要通过分割的方法来减少chunk的大小,例如一个64MB的chunk分割成2个32MB的chunk,这样虽然增加了chunk的数量,但是带来的收益是单个chunk的缩小 。
文章插图
chunk的迁移
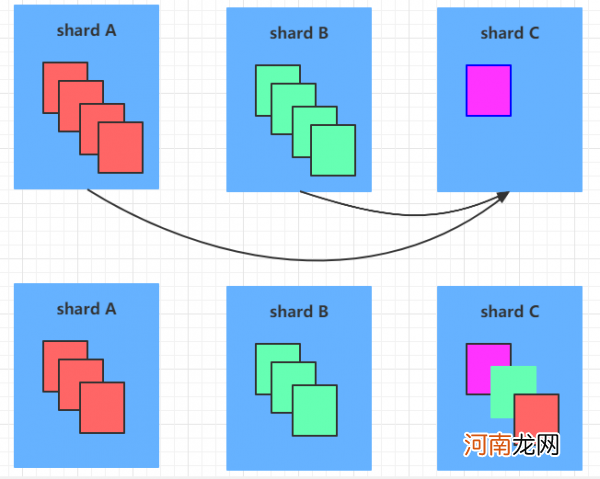
在分片+复制集的架构中,当某个服务器上的数据记录不停的增多,它上面分割的chunk就会变多,当集群中每个服务器上的chunk数量严重失衡的时候,mongodb会自动进行chunk的迁移工作,这个自动迁移的工作,是通过balancer来进行的 。如果balancer发现各个shard之间的chunk数差异超过了提前规定的阈值,则会进行chunk的迁移工作,如下:
文章插图
也就是从上面的状态变成下面的状态 。每个小块代表一个chunk 。
MongoDB自动触发迁移的阈值表如下:
chunk数量: <20,迁移阈值:2
chunk数量:20~79,迁移阈值:4
chunk数量: >80,迁移阈值:8
chunk的迁移一般使用锁来实现,从MongoDB3.4版本起,chunk的迁移分为7个步骤:
1、balancer进程将moveChunk的命令发送到源shard中
2、源shard使用内部moveChunk命令开始移动,迁移过程中,该chunk的操作依旧在源shard上进行,源shard依旧负责该chunk的写入操作
3、目标shard开始创建所需索引
4、目标shard开始请求chunk中的文档并开始接收数据的复制
5、接收完源shard的最后一个文档之后,目标shard启动一个同步进程,这个进程会拉取迁移期间的日志,将迁移期间对该chunk的操作更新到目标chunk中 。
6、当完全同步时,源shard连接到config数据库并更新chunk的位置元数据 。
7、完成数据更新后,一旦在源shard上没有对该chunk的操作,源shard会异步删除chunk 。当然,用户可以设置_waitforDelete参数为true,让源shard在chunk迁移完成后同步删除chunk数据
通常情况下,chunk迁移由下面三种场景触发:
1、多个shard上分布不均匀
2、用户调用removeShard之后,被移除的shard上的chunk就要被迁移到其他的shard上
3、MongoDB的shard tag功能,可以对shard或者shard key range打标签,系统会自动将对应的range的数据迁移到拥有相同tag的shard上 。
文章来源:脚本之家
来源地址:https://www.jb51.net/article/209833.htm
【MongoDB的chunk详解】
- Postgresql限制用户登录错误次数的实例代码
- Postgresql设置远程访问的方法
- PostgreSQL用户登录失败自动锁定的处理方案
- PostgreSQL数据库中如何保证LIKE语句的效率
- 快给你的小宝贝右脑充充电
- 帮新生儿洗澡的注意事项
- 宝贝3岁前的自我服务计划
- 父母需谨记护理新生儿部位的禁忌
- 妈妈抱起新生儿时的大禁忌
- 网友分享让孩子长高的N个办法