这篇文章主要介绍了PostgreSQL字符切割:substring函数的用法说明 , 具有很好的参考价值 , 希望对大家有所帮助 。一起跟随小编过来看看吧
【PostgreSQL字符切割:substring函数的用法说明】作为当前最强大的开源数据库 , Postgresql(以下简称pg)对字符的处理也是最为强大的 , 首先他也有substr , trim等其他数据库都有的普通函数 , 这里我们介绍他更强大的一个函数substring , 可以像python , java等编程语言一样使用正则表达式 , 强大到极点
在此之前我们先了解一下正则表达式最基础的四个
%代表一个或多个字符 _代表一个字符 ^代表字符前 $代表字符后
pg的官网上对其用法是下面这样 , 但不够清楚了然 , 下面我一一解释

文章插图
第一个
用法和substr差不多 , 是指定序列 , from 2 for 3 是从序列为2的位置开始取3个字符 。例子如上
第二个
例子用法的意思是:$代表字符后, 一个点代表一个字符 , 即从最末尾开始选择3个字符 , 同样的如果是substring(‘Thomas’ from ‘^….’) 则结果是Thom
第三个
用法是最实用的 , 也是最难理解的 , 先大致理解:
from ‘%#”o_a#”_’ for ‘#’ 中from是开始(包含),for后面跟的是逃逸 , 即结束
这个例子的意思是我想要o_a的组合字符 , 其中o_a的多个(%)字符不要 , 后面的一个(_)字符不要 , 这里要注意的是切分后面剩多少字符写几个_
这里的架构可以理解为固定的 , 即 from ‘#”#”‘ for ‘#’ #” 是分割字符 , 可以在#”前中后限定选择你最想要的字符
下面用实例来讲解一下第三个用法
需求:下图的查询结果是查的日志表,我想要【】里的数据 , 由于【】里字符长度不固定 , 又只能用sql来切割 , 因此只能使用第三种方法来获取【】里的数据
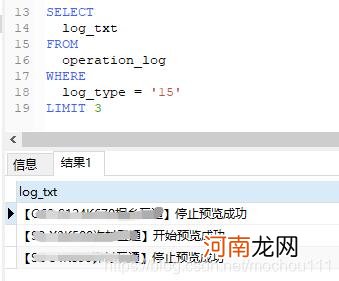
文章插图
解决1:
根据上面的思想 , 我可以写这样的架构’【#”%#”_______’ FOR ‘#’ , 试着运行一下
SELECT
SUBSTRING (
log_txt
FROM
‘【#”%#”_______’ FOR ‘#’
) log_txt
FROM
operation_log
WHERE
log_type = ’15’
LIMIT 3

文章插图
解决2:
也可以根据position这个函数来解决 , 这个函数类似于python的index , 就是把字符串的某个字符转变为该字符所在的位置数 , 如此一来便可以使用substring的第一个例子用法 , 即
1SUBSTRING ( log_txt FROM 2 FOR position(‘【’))
ooook 搞定了!!!
补充:Postgresql之split_part()切割函数
如下所示:
1split_part(string text, delimiter text2, field int)
text要切割的字段; text2按照什么形式切割 int截取的位置
ps:
text=“name.cn” split_part(text,’.’,1) 结果: name
text=“name.cn” split_part(text,’.’,2) 结果: cn
text=“name.cn.com” split_part(text,’.’,3) 结果: com
文章来源:脚本之家
来源地址:https://www.jb51.net/article/205165.htm
- PostgreSQL 字符串处理与日期处理操作
- postgresql 中的to_char常用操作
- postgresql 中position函数的性能详解
- PostGreSql 判断字符串中是否有中文的案例
- vsc系统故障的原因,vsc是什么故障灯
- 后叶子板什么程度才需要切割?叶子板更换是事故车吗
- PostgreSQL将数据加载到buffer cache中操作方法
- 在PostgreSQL中使用ltree处理层次结构数据的方法
- Postgresql限制用户登录错误次数的实例代码
- Postgresql设置远程访问的方法