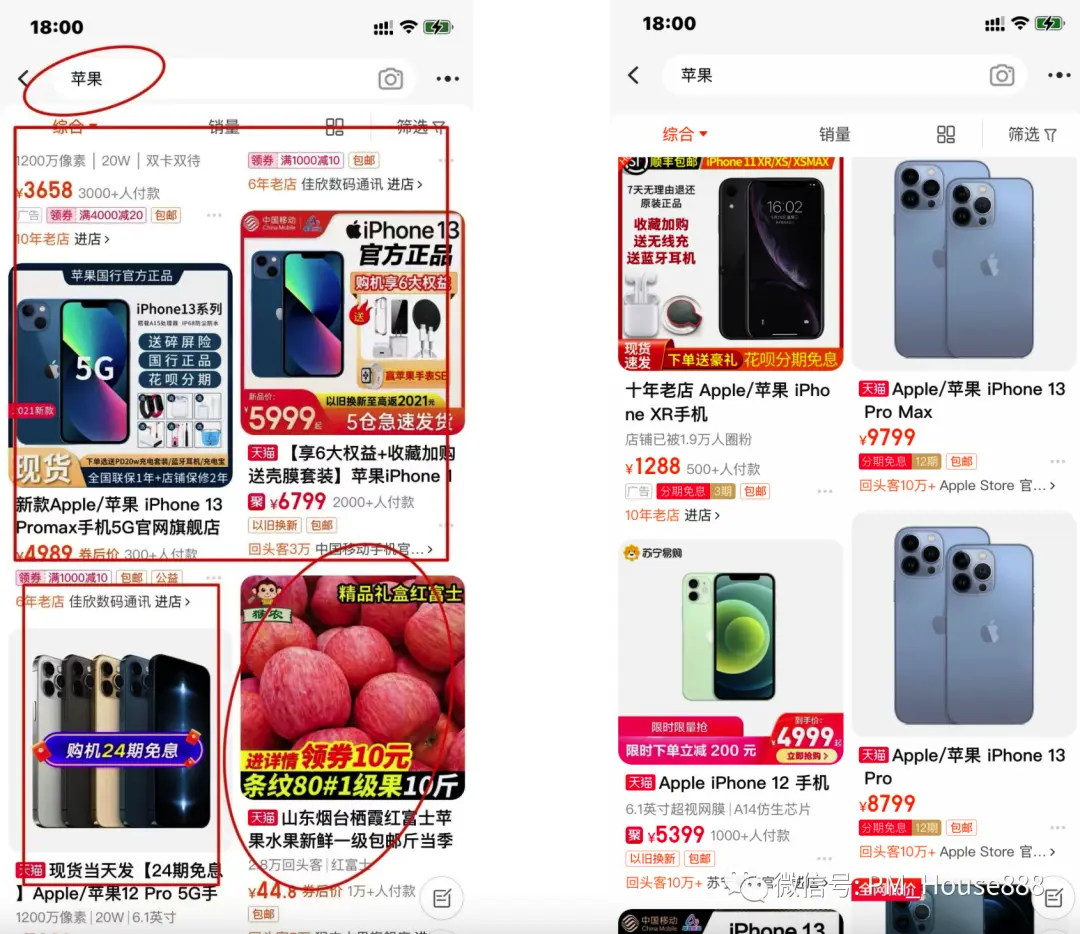
第一张图:搜索的关键字是“苹果” , 既有手机类的商品也有食物类的商品 , 左图就是典型的没有使用类目预测模型来打分 , 所以把食物类的苹果也召回并且优先排序在前面 , 右图是使用后类目预测模型后的打分排序效果;
文章插图
用户输入“苹果” , 查询到一批商品 , 这些商品中有一部分的商品类目是“手机类” , 另一部分的商品类目是“食物类” , 根据计算机大数据对全量用户的搜索历史行为分析得出 , 搜索“苹果”的人里面 , 点击“手机类”类目商品的人要比点击“食物类”类目商品的人多得多 , 则类目预测就会给出这样的预测结果:“手机类”类目与“苹果”的相关度要比“食物类”类目与“苹果”的相关度高 , 所以在计算每个商品的相关算分时 , “手机类”类目商品的算分值就会比“食物类”类目的商品算分值高 , 因此“手机类”类目的商品会排在更前面 , 这样就提高了搜索的业务价值;
所以我们在做产品原型设计的时候也要考虑搜索的关键词与商品类目的相关程度 , 需要在原型的设计里面增加类目预测的模型的设计;
再来回过头看 , 我前面讲的 , 排序首选要进行海选也就是粗排 , 再针对粗排后的商品结果进行精排 , 粗排已经讲了 , 精排怎么排?
同样是要通过函数去计算搜索的关键词与商品的相关度 , 常见的函数有:
文本相关度函数:
- text_relevance: 关键词在字段上的商品匹配度
- field_match_ratio:获取某字段上与查询词匹配的分词词组个数与该字段总词组个数的比值
- query_match_ratio:获取查询词中(在某个字段上)命中词组个数与总词组个数的比值
- fieldterm_proximity: 用来表示关键词分词词组在字段上的紧密程度
- field_length:获取某个字段上的分词词组个数
- query_term_count: 返回查询词分词后词组个数
- query_term_match_count:获取查询词中(在某个字段上)命中文档的词组个数
- field_term_match_count:获取文档中某个字段与查询词匹配的词组个数
- query_min_slide_window:查询词在某个字段上命中的分词词组个数与该词组在字段上最小窗口的比值
- distance: 获取两个点之间的球面距离 。一般用于LBS的距离计算 。
- gauss_decay , 使用高斯函数 , 根据数值和给定的起始点之间的距离 , 计算其衰减程度
- linear_decay , 使用线性函数 , 根据数值和给定的起始点之间的距离 , 计算其衰减程度
- exp_decay , 使用指数函数 , 根据数值和给定的起始点之间的距离 , 计算其衰减程度
- timeliness: 时效分 , 用于衡量商品的新旧程度 , 单位为秒
- timeliness_ms: 时效分 , 用于衡量商品的新旧程度 , 单位为毫秒
- category_score:类目预测函数 , 返回参数中指定的类目字段与类目预测query的类目匹配分
- popularity:人气分 , 用于衡量物品的受欢迎程度
- tag_match: 用于对查询语句和商品做标签匹配 , 使用匹配结果对商品进行算分加权
- first_phase_score:获取粗排表达式最终计算分值
- 多渠道时代下,电商的隐性赛道转换
- 剖宫产后多久适合怀孕 剖腹产后多久可以生二胎
- IP运营详解,三步打造独一无二的IP
- 娱乐化互动:会是电商行业的下一个主题吗?
- 惜别公域流量红利,流量电商的终局在哪?
- 新团队该如何入局私域电商?
- 怎么让文案写出搜索引擎喜欢的seo文章?工作流程拆解
- 如何把新账户ocpc的0门槛进二阶和降低成本?
- SEM竞价搜索:如何快速诊断账户?
- 百度搜索下拉框刷词与点击快排原理是什么?做快排降权怎么办?