- 聚类是一种无监督类分析方法,无法自动发现应该分成多少个类;
- 期望能很清楚的找到大致相等的类或细分市场是不现实的;
- 样本聚类,变量之间的关系需要研究者决定;
- 不会自动给出一个最佳聚类结果 。
(1)选择聚类变量
在选取特征的时候,我们会根据一定的假设,尽可能选取对产品使用行为有影响的变量,这些变量一般包含与产品密切相关的用户态度、观点、行为 。但是,聚类分析过程对用于聚类的变量还有一定的要求: 1.这些变量在不同研究对象上的值具有明显差异;2.这些变量之间不能存在高度相关 。
首先,用于聚类的变量数目不是越多越好,没有明显差异的变量对聚类没有起到实质意义,而且可能使结果产生偏差;其次,高度相关的变量相当于给这些变量进行了加权,等于放大了某方面因素对用户分类的作用 。识别合适的聚类变量的方法:1.对变量做聚类分析,从聚得的各类中挑选出一个有代表性的变量;2.做主成份分析或因子分析,产生新的变量作为聚类变量 。
【用户画像分群:增长分析必杀技?】(2)聚类分析
相对于聚类前的准备工作,真正的执行过程显得异常简单 。数据准备好后,导入到统计工具中跑一下,结果就出来了 。这里面遇到的一个问题是,把用户分成多少类合适?通常,可以结合几个标准综合判断: 1.看拐点(层次聚类会出来聚合系数图,一般选择拐点附近的几个类别);2.凭经验或产品特性判断(不同产品的用户差异性也不同);3.在逻辑上能够清楚地解释 。
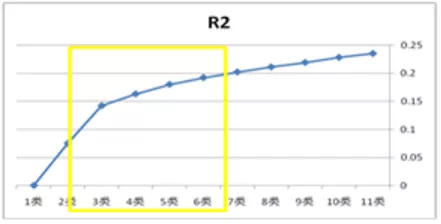
文章插图
图2:聚合系数图
(3)找出各类用户的重要特征
确定一种分类方案之后,接下来,我们需要返回观察各类别用户在各个变量上的表现 。根据差异检验的结果,我们以颜色区分出不同类用户在这项指标上的水平高低 。其他变量以此类推 。最后,我们会发现不同类别用户有别于其他类别用户的重要特征 。
(4)聚类解释和命名
在理解和解释用户分类时,最好可以结合更多的数据,例如,人口统计学数据、功能偏好数据等等 。然后,选取每一类别最明显的几个特征为其命名,大功告成 。
五、K-means聚类在用户分群中的应用案例
在本案例中,我们首先来看最常用的K-Means聚类法(也叫快速聚类法),这是非层次聚类法当中最常用的一种 。因其简单直观的计算方法和比较快的速度(相对层次聚类法而言),进行探索性分析时,K-Means往往是第一个采用的算法 。并且,由于其广泛被采用,在协作沟通时也节省了不少用于解释的时间成本 。
1. K-means的算法原理:
- 随机取k个元素,作为k个簇各自的中心 。
- 计算剩下的元素到k个簇中心的相似度,将这些元素分别划归到相似度最高的簇 。
- 根据聚类结果,重新计算k个簇各自的中心,计算方法是取簇中所有元素各自维度的算术平均数 。
- 将全部元素按照新的中心重新聚类 。
- 重复第4步,直到聚类结果不再变化,然后结果输出 。
- 三大运营商|三大运营商删除行程卡用户数据是怎么回事 行程卡都包含用户哪些数据
- 用户名字母数字下划线是什么意思
- 微信辅助对自己的微信有什么影响
- 抖音搜索用户不进主页会被发现吗
- 拼多多退货运费谁承担
- 微信吞消息是什么原因
- 和彩云至高支持普通会员用户上传多大的大文件?
- 空调舒适温度是多少
- icloud云盘是什么
- 极速退款条件