2. 分析目标
- 发现使用行为模式异于大盘典型用户的细分群体
- 粗估每个细分群体的用户数量
- 了解每个细分群体的行为特征和用户画像
- 基于上述结果,在拉活方面,提出产品或运营建议或明确进一步探索的方向
a) 特征提取
分析聚焦于用户的点击行为 。在本例中,考虑到用户行为的典型性,选取了4个完整的周,共28天的数据,并且时间窗当中无任何节日 。另外,考虑到计算性能和探索性分析需要反复迭代的场景,只从大盘当中随机抽取千份之一的用户作为代表 。
b) 特征筛选
在特征提取阶段一共提取了接近200个功能点的点击数据 。但是这些特征当中,有些覆盖面非常低,只有百份之一的用户在28天当中曾经使用,这些低覆盖的特征会首先被去除 。
另外,前面谈到高度相关的变量也会干扰聚类过程,这里对所有特征对两两进行计算皮尔逊相关系数,对高相关特征(相关系数大于0.5)则只保留其中保留覆盖面最广的特征,以便最大限度地体现用户差异 。
c) 特征改造-探索
经过上面两步后,笔者曾进行过多次聚类探索,但无一例外,聚类结果都呈现出一个超级大类搭配数十个非常小的小类(几个或十几个用户) 。这样的结果,显然与我们的分析目标是想违背的 。其一,这里挖掘出的小群体体积太小,从业务角度来说没有价值;其二,超级大类基本等同与大盘用户,没有能找出其中的用户差异 。
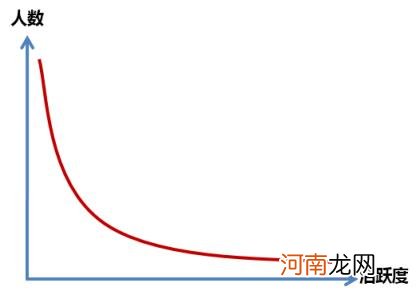
为什么会有这样的结果呢,主要是因为点击行为基本上遵循的是幂率分布,大量用户集中在低频次区间,而极少量用户却会有极高的频次,这样在典型的聚类算法中,高频次用户都会被聚集成人数极少的小类,而大量的低频词用户就会被聚集成一个超级大类 。
文章插图
文章插图
图5:点击行为分布
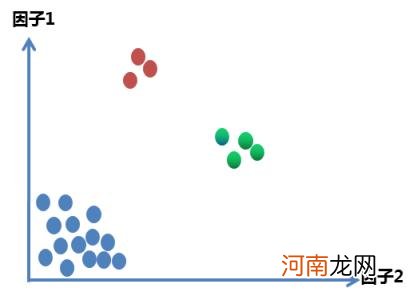
图6:点击行为数K-Means聚类示意图
对于这种情况,典型的解决方法是对频次取对数,使幂率分布转化为近似的正态分布再进行聚类,在本次研究中,取自然对数后,聚类效果仅有少量改善,但仍然停留在一个超级大类加上若干人数极少的小类的情况 。背后原因,是点击行为数据的特点之一:核心功能和热门项目点击人数极多,而相对冷门的功能则有大量的0值 。这样的情况下,取对数是没有改善的 。

文章插图

文章插图
图7:打开次数分布
图8:打开次数分布(自然对数变换)
回到本次分析的目标当中,我们需要“发现使用行为模式异于大盘典型用户的细分群体”,如果丢弃这些冷门功能只看热门选项,则无法找出一些相对小众的行为模式达成分析目标 。而这种数值稀疏的情况则让笔者想起了文本分类 。在文本分类的词袋模型当中,每个“文档“的词向量同样存在大量的0值,词袋模型的解决方法是对词向量用TF-IDF方法进行加权 。下面简单介绍这种方法
d) 特征改造-TF-IDF
在文本分类的词袋模型当中,需要将一篇篇“文档”(Document)(例如一篇新闻,一条微博,一条说说)按照其讨论的主题聚合在一起,而一篇文档里面有很多词(Term) 。TF(Term Frequency 词频率)就是指一个词在一篇文档里的出现次数在整篇文档总词数当中的占比,这样简单的计算就知道一篇文档中什么词更多,而不会受到文档本身长度的影响 。
- 三大运营商|三大运营商删除行程卡用户数据是怎么回事 行程卡都包含用户哪些数据
- 用户名字母数字下划线是什么意思
- 微信辅助对自己的微信有什么影响
- 抖音搜索用户不进主页会被发现吗
- 拼多多退货运费谁承担
- 微信吞消息是什么原因
- 和彩云至高支持普通会员用户上传多大的大文件?
- 空调舒适温度是多少
- icloud云盘是什么
- 极速退款条件