另一方面,有些词是是什么文章都会用的“大众”词,这些词对于文章主题的分辨是没什么帮助的(例如新闻当中的“报道”“采访人员”等等) 。对于这样的“大众”词,就要降低他的权重,所以可以通过(文档总数/含有某个词的文档数)这样的计算达到目的,每篇文章都有的词权重会取0,包含的文档数越少,数值越大 。这计算就是IDF(Inverse Document Frequency 逆文档频率) 。
按照上面的讨论,读者可能已经想到了,如果把“文档”的概念变为“用户”,把“词的出现次数”替换为“功能的点击次数“,就正好可以用来把用户行为的类型进行分类 。首先是低频率用户的功能偏好会通过TF的计算得到反映,不会因为总体上用得少在与高频用户的对比当中被笼统归为一个低频用户的类 。同时IDF也让一些小众功能有更大的权重,更容易在聚类中突出小众偏好 。
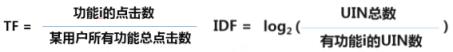
文章插图
e) 聚类结果
通过这样的特征改造,再用K-Means算法进行聚类,得出的结果就比较符合分析目标了,从大盘数据中,我们找到了各种具有鲜明行为特色的群体,并且初略估计出了各个群体的大小,行为特征和背景特征 。并在此基础上结合用户研究数据去探索产品改进的建议 。
八、小结
用户分群对于用户数据研究领域最大的改变,在于打破数据孤岛并真实了解用户 。分析某个指标数字背后的用户具备哪些特征(他们的人群属性、行为特点等),进而发现产品问题背后的原因,并从中发现产品有效改进提升的机会或方向 。
在进行聚类分析时,特征的选择和准备非常重要:1. 合适的变量在各个样本之类需要有明显差异;2.变量之间不能有强相关关系,否则需要用PCA等方法先进行降维;3.需要根据数据本身的特点和业务特性对数据进行变换(如标准化,取对数等);
而聚类算法的选择则需要结合数据特点(是否有变量,离群值,数据量,是否成簇状),以及计算速度(探索性分析往往需要较快的计算速度),精确度(能否精确识别出群落)等方面去选择合适的算法 。对算法中的参数,例如K-Means当中的类别数K,则需要结合技术指标和业务背景,选取逻辑上说得通的分类方案 。
聚类算法有非常多,各有其特点和擅长的地方,本文仅举其中两个较常用的方法为例,抛砖引玉,希望对读者有所启发 。
好了,这篇文章的内容蜀川号就和大家分享到这里!
- 三大运营商|三大运营商删除行程卡用户数据是怎么回事 行程卡都包含用户哪些数据
- 用户名字母数字下划线是什么意思
- 微信辅助对自己的微信有什么影响
- 抖音搜索用户不进主页会被发现吗
- 拼多多退货运费谁承担
- 微信吞消息是什么原因
- 和彩云至高支持普通会员用户上传多大的大文件?
- 空调舒适温度是多少
- icloud云盘是什么
- 极速退款条件